
Step1: – Import libraries
import os
import selenium
from selenium import webdriver
import time
from PIL import Image
import io
import requests
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import ElementClickInterceptedException
Step 2: – Install Driver
#Install Driver
driver = webdriver.Chrome(ChromeDriverManager().install())
Step 3: – Specify search URL
#Specify Search URL
search_url=“https://www.google.com/search?q={q}&tbm=isch&tbs=sur%3Afc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568"
driver.get(search_url.format(q='Car'))
we’re searching for Car in our Search URL Paste the link into to driver.get(“ Your Link Here ”) function and run the cell. This will open a new browser window for that link.
Step 4: – Scroll to the end of the page
#Scroll to the end of the page
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)#sleep_between_interactions
This line of code would help us to reach the end of the page. And then we’re giving sleep time of 5 seconds so we don’t run into a problem, where we’re trying to read elements from the page, which is not yet loaded.
Step 5: – Locate the images to be scraped from the page
#Locate the images to be scraped from the current page
imgResults = driver.find_elements_by_xpath("//img[contains(@class,'Q4LuWd')]")
totalResults=len(imgResults)
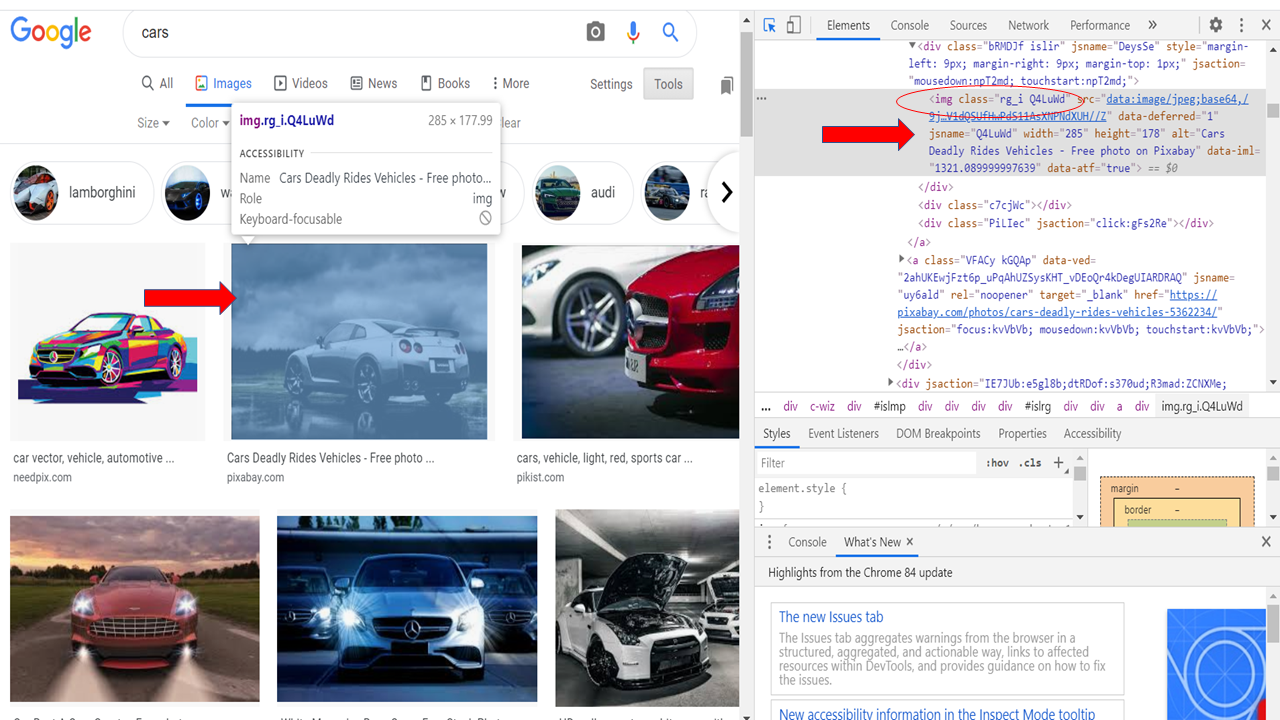
Now we’ll fetch all the image links present on that particular page. We will create a “list” to store those links. So, to do that go to the browser window, right-click on the page, and select ‘inspect element’ or enable the dev tools using Ctrl+Shift+I.
Now identify any attributes such as class, id, etc. Which is common across all these images.
In our case class =”‘Q4LuWd” is common across all these images.
Step 6: – Extract the corresponding link of each Image
As we can the images are shown on the page are still the thumbnails not the original image. So to download each image, we need to click each thumbnail and extract relevant information corresponding to that image.
#Click on each Image to extract its corresponding link to download
img_urls = set()
for i in range(0,len(imgResults)):
img=imgResults[i]
try:
img.click()
time.sleep(2)
actual_images = driver.find_elements_by_css_selector('img.n3VNCb')
for actual_image in actual_images:
if actual_image.get_attribute('src') and 'https' in actual_image.get_attribute('src'):
img_urls.add(actual_image.get_attribute('src'))
except ElementClickInterceptedException or ElementNotInteractableException as err:
print(err)
So, in the above snippet of code, we’re performing the following tasks-
- Iterate through each thumbnail and then click it.
- Make our browser sleep for 2 seconds (:P).
- Find the unique HTML tag corresponding to that image to locate it on page
- We still get more than one result for a particular image. But all we’re interested in the link for that image to download.
- So, we iterate through each result for that image and extract ‘src’ attribute of it and then see whether “https” is present in the ‘src’ or not. Since typically weblink starts with ‘https’.
Step 7: – Download & save each image in the Destination directory
os.chdir('C:/Qurantine/Blog/WebScrapping/Dataset1')
baseDir=os.getcwd()
for i, url in enumerate(img_urls):
file_name = f"{i:150}.jpg"
try:
image_content = requests.get(url).content
except Exception as e:
print(f"ERROR - COULD NOT DOWNLOAD {url} - {e}")
try:
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert('RGB')
file_path = os.path.join(baseDir, file_name)
with open(file_path, 'wb') as f:
image.save(f, "JPEG", quality=85)
print(f"SAVED - {url} - AT: {file_path}")
except Exception as e:
print(f"ERROR - COULD NOT SAVE {url} - {e}")
Now finally you have extracted the image for your project 
Note: – Once you have written proper code then the browser is not important you can collect data without browser, which is called headless browser window, hence replace the following code with the previous one.
Headless Chrome browser
#Headless chrome browser
from selenium import webdriver
opts = webdriver.ChromeOptions()
opts.headless =True
driver =webdriver.Chrome(ChromeDriverManager().install())
In this case, the browser will not run in the background which is very helpful while deploying a solution in production.
Let’s put all this code in a function to make it more organizable and Implement the same idea to download 100 images for each category (e.g. Cars, Horses).
And this time we’d write our code using the idea of headless chrome.
Putting it all together:
Step 1 – Import all required libraries
import os
import selenium
from selenium import webdriver
import time
from PIL import Image
import io
import requests
from webdriver_manager.chrome import ChromeDriverManager
os.chdir('C:/Qurantine/Blog/WebScrapping')
Step 2 – Install Chrome Driver
#Install driver
opts=webdriver.ChromeOptions()
opts.headless=True
driver = webdriver.Chrome(ChromeDriverManager().install() ,options=opts)
In this step, we’re installing a Chrome driver and using a headless browser for web scraping.
Step 3 – Specify search URL
search_url = "https://www.google.com/search?q={q}&tbm=isch&tbs=sur%3Afc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568"
driver.get(search_url.format(q='Car'))
I’ve used this specific URL to scrape copyright-free images.
Step 4 – Write a function to take the cursor to the end of the page
def scroll_to_end(driver):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)#sleep_between_interactions
This snippet of code will scroll down the page
Step5. Write a function to get URL of each Image
#no license issues
def getImageUrls(name,totalImgs,driver):
search_url = "https://www.google.com/search?q={q}&tbm=isch&tbs=sur%3Afc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568"
driver.get(search_url.format(q=name))
img_urls = set()
img_count = 0
results_start = 0
while(img_count<totalImgs): #Extract actual images now
scroll_to_end(driver)
thumbnail_results = driver.find_elements_by_xpath("//img[contains(@class,'Q4LuWd')]")
totalResults=len(thumbnail_results)
print(f"Found: {totalResults} search results. Extracting links from{results_start}:{totalResults}")
for img in thumbnail_results[results_start:totalResults]:
img.click()
time.sleep(2)
actual_images = driver.find_elements_by_css_selector('img.n3VNCb')
for actual_image in actual_images:
if actual_image.get_attribute('src') and 'https' in actual_image.get_attribute('src'):
img_urls.add(actual_image.get_attribute('src'))
img_count=len(img_urls)
if img_count >= totalImgs:
print(f"Found: {img_count} image links")
break
else:
print("Found:", img_count, "looking for more image links ...")
load_more_button = driver.find_element_by_css_selector(".mye4qd")
driver.execute_script("document.querySelector('.mye4qd').click();")
results_start = len(thumbnail_results)
return img_urls
This function would return a list of URLs for each category (e.g. Cars, horses, etc.)
Step 6: Write a function to download each Image
def downloadImages(folder_path,file_name,url):
try:
image_content = requests.get(url).content
except Exception as e:
print(f"ERROR - COULD NOT DOWNLOAD {url} - {e}")
try:
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert('RGB')
file_path = os.path.join(folder_path, file_name)
with open(file_path, 'wb') as f:
image.save(f, "JPEG", quality=85)
print(f"SAVED - {url} - AT: {file_path}")
except Exception as e:
print(f"ERROR - COULD NOT SAVE {url} - {e}")
This snippet of code will download the image from each URL.
Step7: – Write a function to save each Image in the Destination directory
def saveInDestFolder(searchNames,destDir,totalImgs,driver):
for name in list(searchNames):
path=os.path.join(destDir,name)
if not os.path.isdir(path):
os.mkdir(path)
print('Current Path',path)
totalLinks=getImageUrls(name,totalImgs,driver)
print('totalLinks',totalLinks)
if totalLinks is None:
print('images not found for :',name)
continue
else:
for i, link in enumerate(totalLinks):
file_name = f"{i:150}.jpg"
downloadImages(path,file_name,link)
searchNames=['Car','horses']
destDir=f'./Dataset2/'
totalImgs=5
saveInDestFolder(searchNames,destDir,totalImgs,driver)



